Epochs, Batches, Batch Size & Iterations — A Beginner’s Guide
TL;DR (Cheat‑Sheet)
- Epoch = one full pass over the dataset.
- Batch = a small chunk of data used for one update step.
- Batch size = how many samples per batch.
- Iteration = one parameter update (one batch step).
The Big Picture (Why These Terms Exist)
We rarely update model weights using the entire dataset at once. Instead, we split the data into batches and update weights after each batch. Repeating this process over the whole dataset is one epoch; doing that multiple times is training for many epochs. Each iteration is a single update step using one batch.
Mental model: Think of studying a textbook. A batch is a chapter you study before you take notes. An epoch is finishing the entire book once. An iteration is one “study + notes” cycle for a chapter.
Tiny Example (12 Samples, Batch Size 4)
- Dataset: 12 samples labeled
0 … 11 - Batch size = 4 → 3 batches per epoch
- Iterations per epoch = 3 (because one iteration per batch)
1
2
3
4
Epoch 1
Iteration 1 → batch [0, 1, 2, 3]
Iteration 2 → batch [4, 5, 6, 7]
Iteration 3 → batch [8, 9, 10, 11]
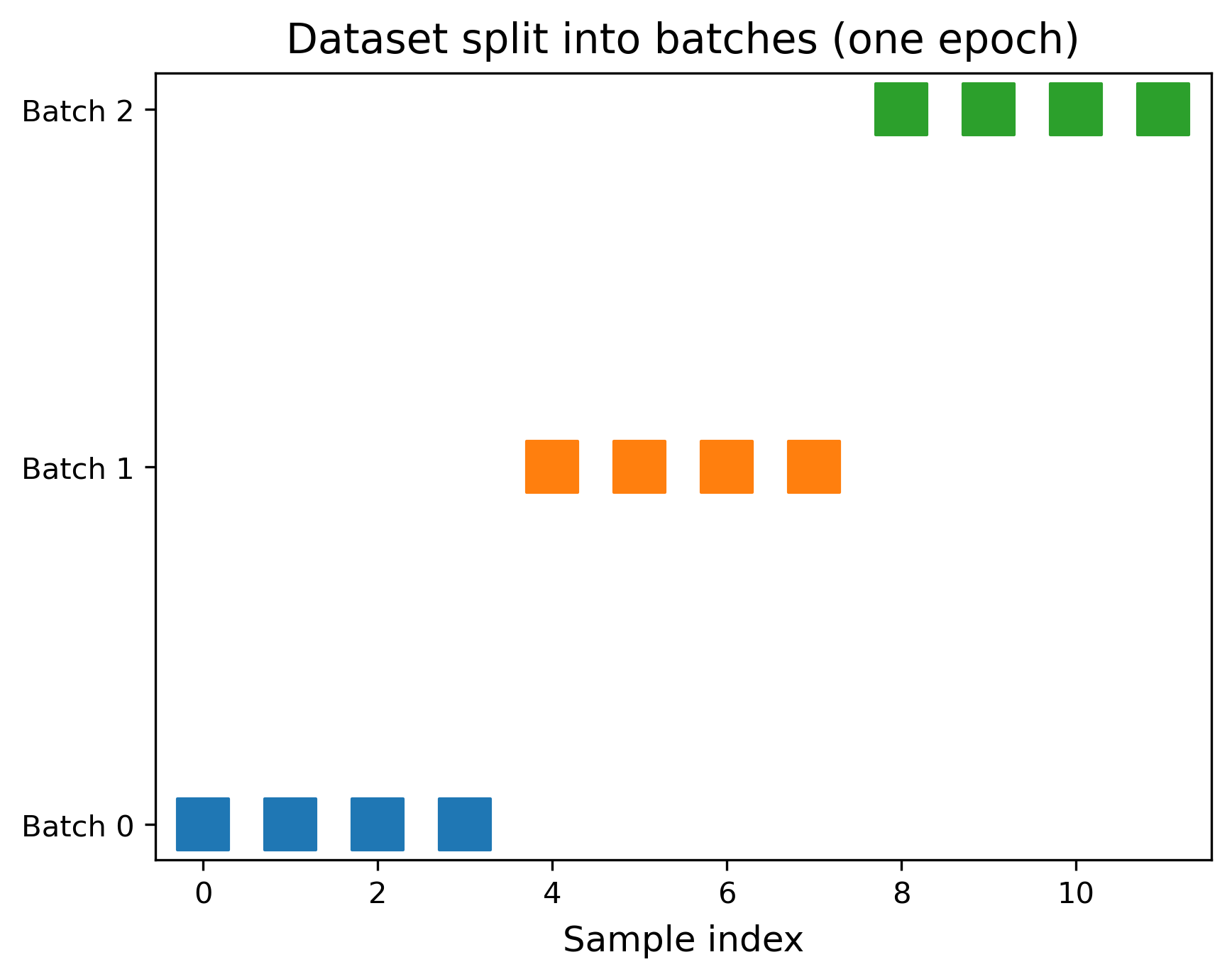
When the dataset size isn’t divisible by the batch size, the last batch is smaller. That’s normal (and most libraries handle it for you).
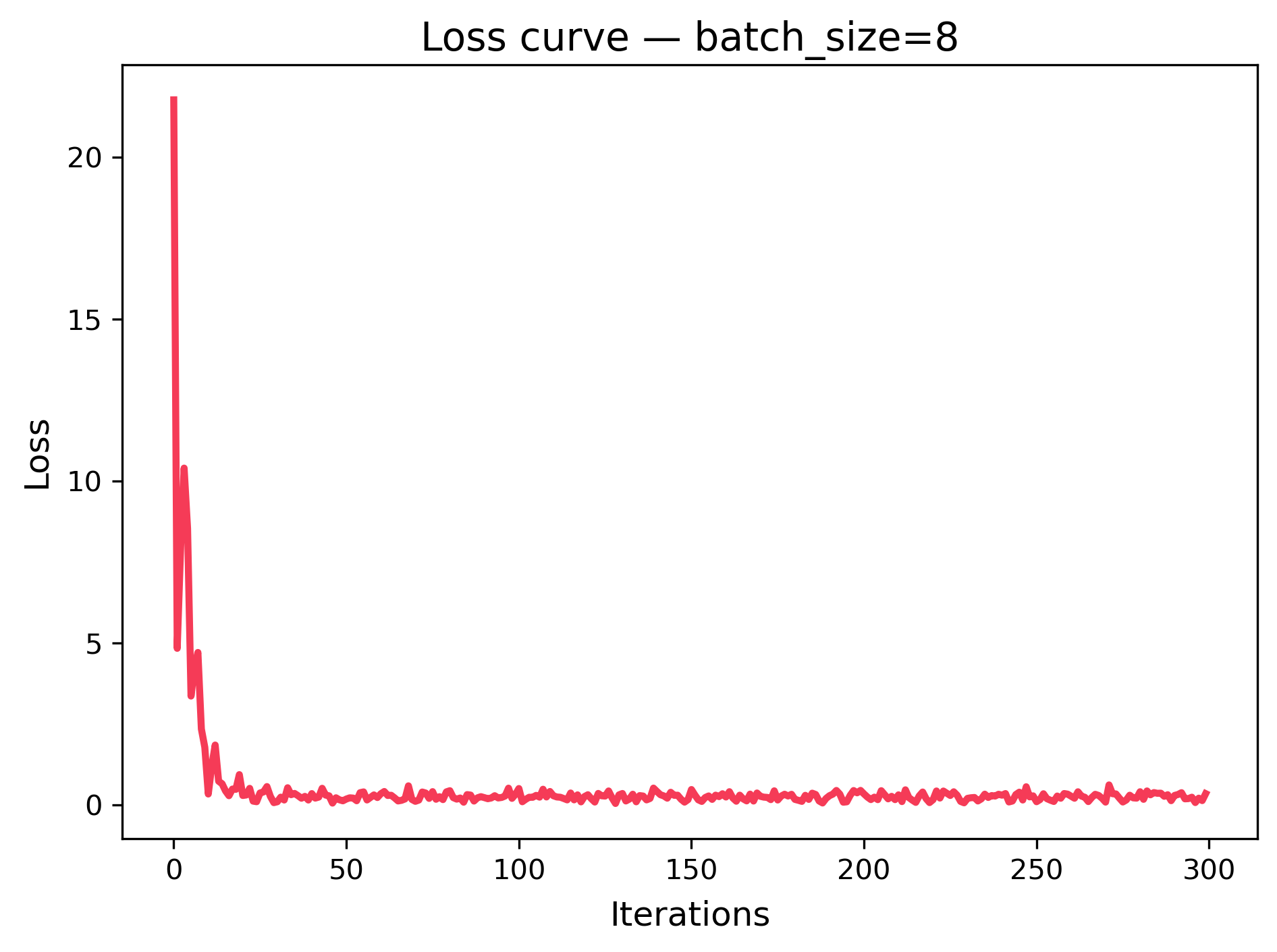
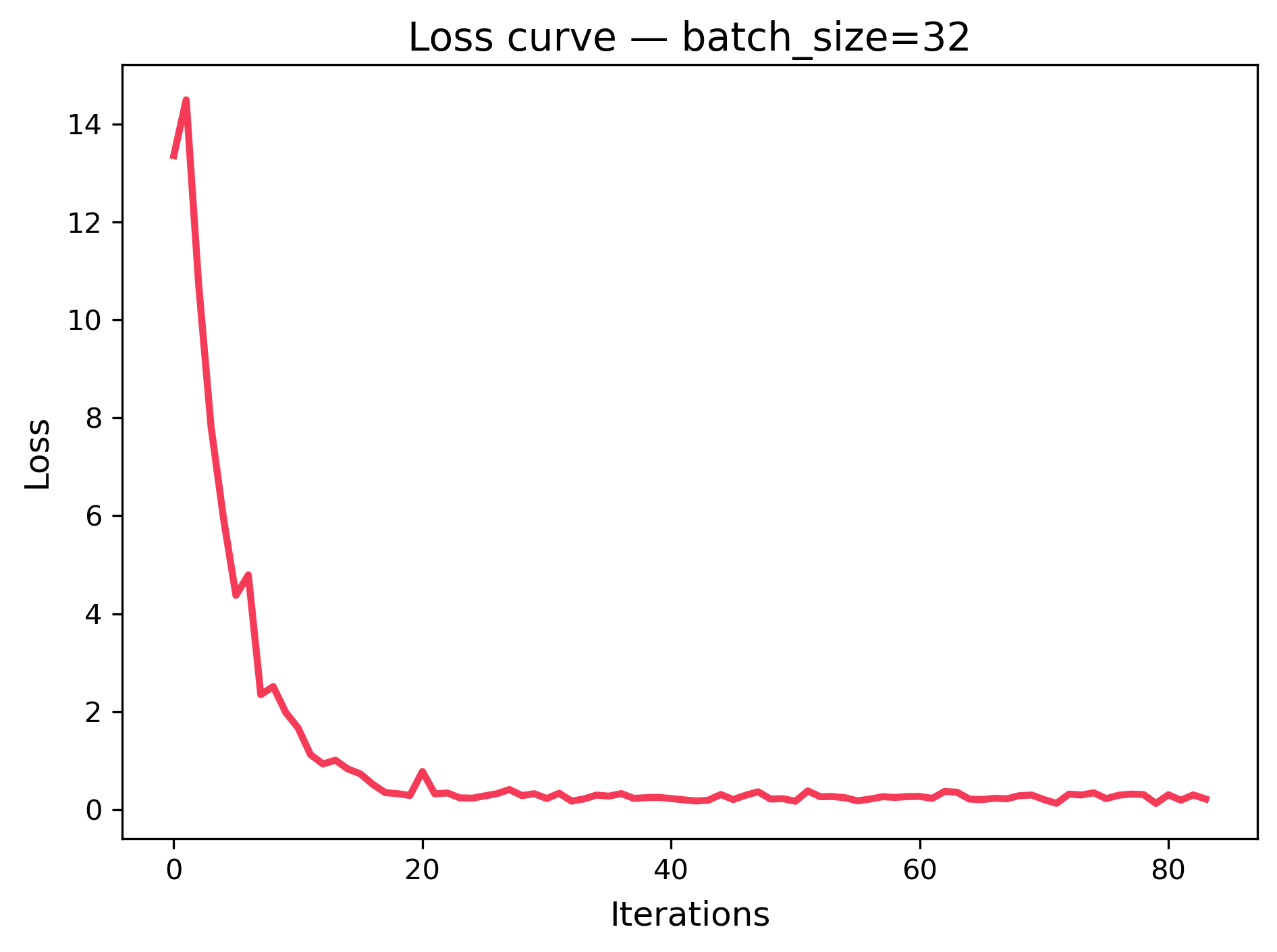
What Changes with Batch Size?
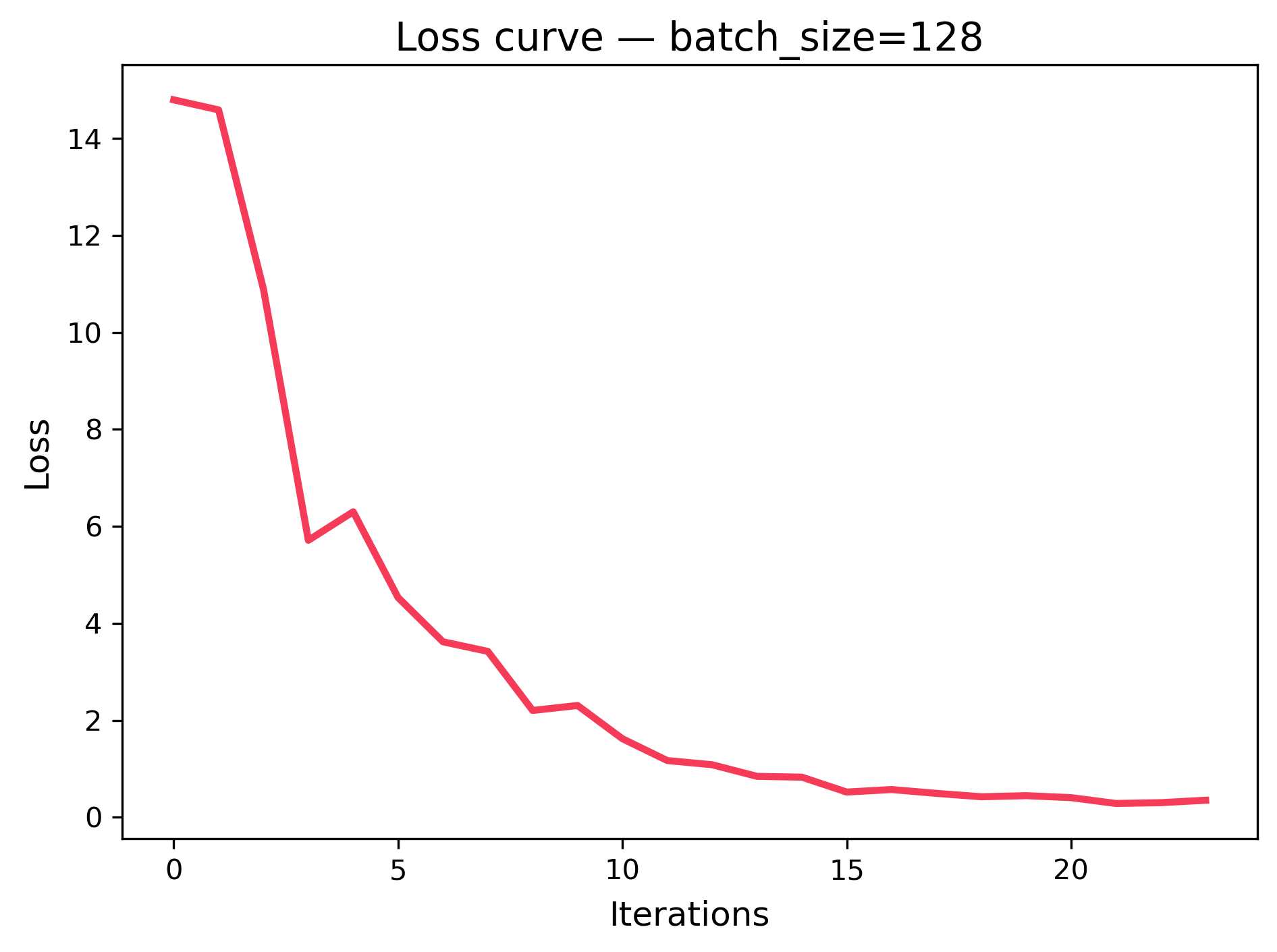
Below are three loss curves from a tiny linear regression trained with different batch sizes (8, 32, 128). The x‑axis is iteration (each update), and the y‑axis is training loss (lower is better).
 |  |  |
|---|---|---|
| batch_size=8 (noisier, more updates) | batch_size=32 (balanced) | batch_size=128 (smoother, fewer updates) |
What to notice:
- Smaller batches → more frequent updates but noisier loss curve.
- Larger batches → smoother curve but fewer updates per epoch.
- All curves generally trend downward → the model is learning.
How Many Epochs? (Underfitting vs Overfitting)
- Too few epochs → model hasn’t learned enough (underfitting).
- Too many epochs → model starts to memorize noise (overfitting).
In practice, we watch validation loss and use early stopping when it stops improving.
Start with a modest number (e.g., 10–30 epochs) and enable early stopping on validation loss. Increase epochs only if you’re still underfitting.
Quick Math You’ll Actually Use
batches_per_epoch = ceil(num_samples / batch_size)iterations_per_epoch = batches_per_epochtotal_iterations = iterations_per_epoch × num_epochs
Common pitfall: Confusing epochs with iterations. If you say “I trained for 100 iterations,” that’s not the same as “100 epochs.” Always check whether a metric is per-epoch or per-iteration.
Minimal Code (PyTorch‑like Pseudocode)
Below is the core training loop you’ll see in many frameworks. The shape is always similar:
1
2
3
4
5
6
7
8
for epoch in range(num_epochs):
for batch_inputs, batch_labels in dataloader: # one batch
# 1) forward pass → predictions
# 2) compute loss
# 3) backward pass → gradients
# 4) optimizer step → update weights
# 5) (optional) zero gradients / clip / log metrics
# (optional) validate once per epoch
Practical Defaults
- Batch size: 16 or 32 if memory is tight; 64–256 if you have GPU memory.
- Epochs: Start small and rely on early stopping.
- Learning rate: If training is unstable, lower the LR or increase batch size.
Wrap‑Up
You now know the vocabulary of training:
- Epoch (full pass), Batch (mini‑chunk), Batch size (how many), Iteration (one update).
These simple ideas explain most training logs you’ll read.
Full notebook: GitHub